

Data is both a dependency and by-product of everything we do – from events in daily life like checkout-less shopping to solving the major problems of the world like a vaccine for Covid-19.
The only question for businesses is whether we are collecting the data and using it for strategic advantage.
Ken Grohe, President and Chief Revenue Officer for Weka, shares his views on the cost of the misuse of data and how businesses can create the foundation for competitive advantage.
If businesses accept that automation, AI, machine learning and smart technologies are the foundation for future operating models, the rate of transformation and change, will necessarily be constrained for organisations who rely on legacy approaches to data management and operations.
Business transformation was traditionally viewed as people, processes and technology. Data is now the fourth leg of the stool. Businesses must understand the inter-related dependencies for each leg and in the act of transformation evolve all legs together – or risk the stool toppling over.
Ken Grohe explains that Weka position themselves as the file system for those who solve big problems. And when they say big problems, they mean the biggest of them all, like the search for a Covid vaccine, data modelling to determine how to prioritise the distribution of a potential Covid vaccine through societies or developing algorithms for self-driving autonomous cars and air transportation.
The value lies in the 80% of data that we do not see - or use.

In any scenario we are aware of data that exists in our field of perspective. But an exponentially greater amount of data exists that we could be collecting and using for effective outcomes.
Grohe aptly used the example of autonomous vehicles. You can see what is on the road ahead of you but you might not see another vehicle in your blind spot, an animal below your range of vision, uneven weight distribution in the vehicle or irregularities of engine performance.
While these examples may be outside of our normal perspective, they are sources of potential data points and complex algorithms are processing all this data in real-time and then applying the outputs to increase safety, comfort and vehicle performance.
The same analogy can be applied to the business world. In any given scenario technology is capable of creating data-points for almost any interaction – the only question is whether your business is collecting, storing and making the data available to decrease risk, improve efficiency or drive revenue.
The barrier for humans, is the time it takes to collect, process and assess volumes of data, from a given number of data sources, in a timely and efficient manner for a given purpose.
But technology removes these constraints in all aspects of data including the generation, collection, storage and processing.
Why is this important? The global Open Exo framework regards data and algorithms as one of the eleven attributes to create ‘exponentially’ scalable 21st century business models.
A new scale of data application for businesses.
And for businesses who leverage this potential there will be a paradigm shift to understand the volumes of data that will routinely be worked with.
When it comes to data, most of us are familiar with the concept megabytes and gigabytes as units of storage capacity or volumes of data.

A bit like a billion follows a million which follows hundreds of thousands data too has an increasing scale. Weka itself is named after a Wekabite, which is 10 to the power of 30 and according to Grohe would support all the possible information that a business might want to process.
Businesses who embark on AI led transformations will step up the data scale and become accustomed to thinking about data capacity in terms of Petabytes and beyond – and traditional or legacy approaches to data management (the act of collecting, storing and data making accessible) will at some point constrain a businesses ability to effectively make use of data in larger scale.
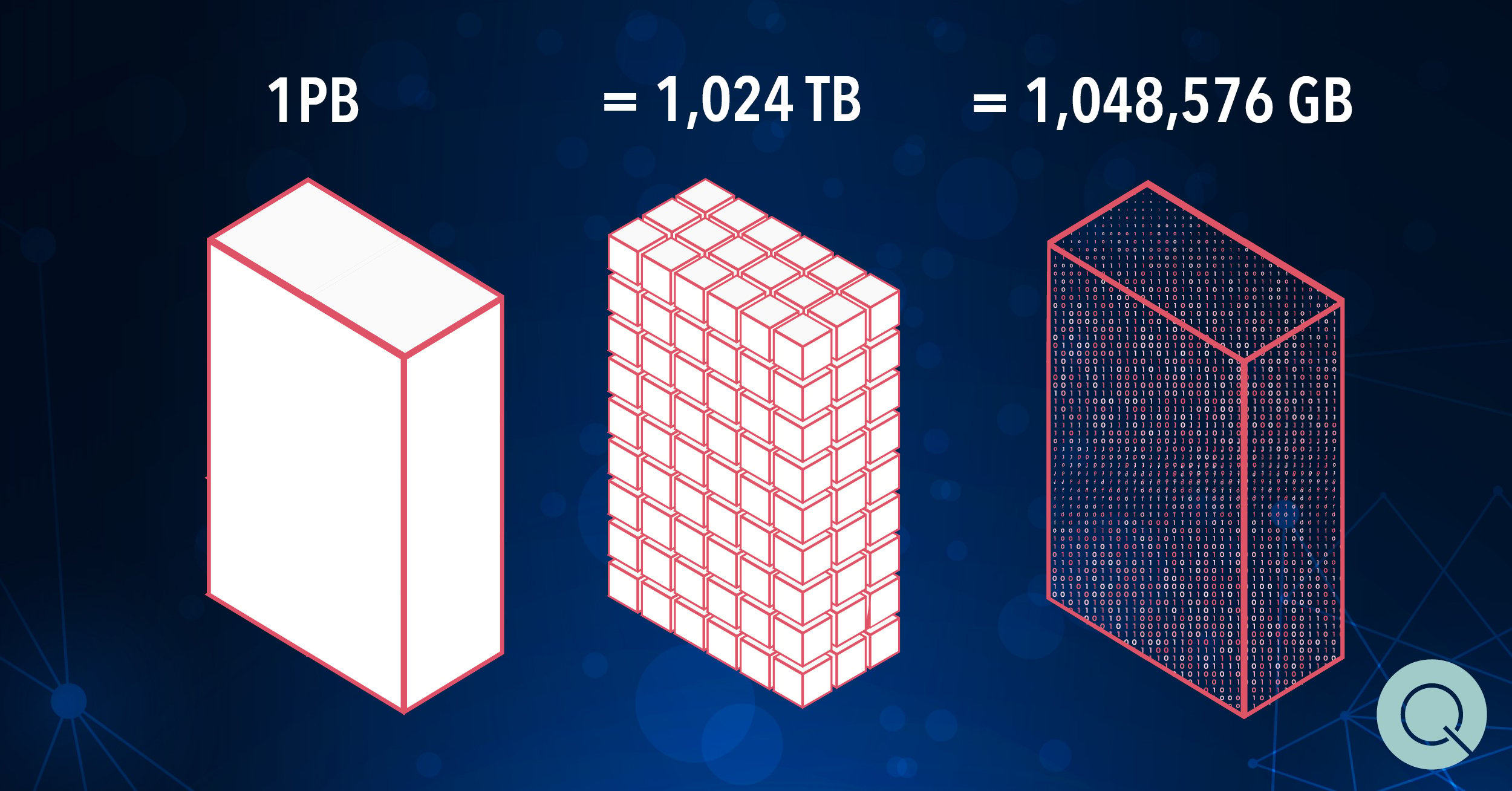
How much data is a petabyte? One petabyte is the equivalent of over 1,000 terabytes which in turn is equivalent to over 1,000,000 gigabytes. One online source compared a petabyte to 20 million four-drawer filing cabinets filled with text documents.
Data management - the future from a technology perspective.
From a technology perspective, Grohe shared the data triangle, a simple concept to help transformers and business leaders understand how to optimise the application of data.
The data triangle is an equilibrium triangle where each one of the three points represents processing, traffic and storage, where the objective is to remove the constraints associated with legacy approaches to data management, for factors like storage capacity, performance, scalability and latency.
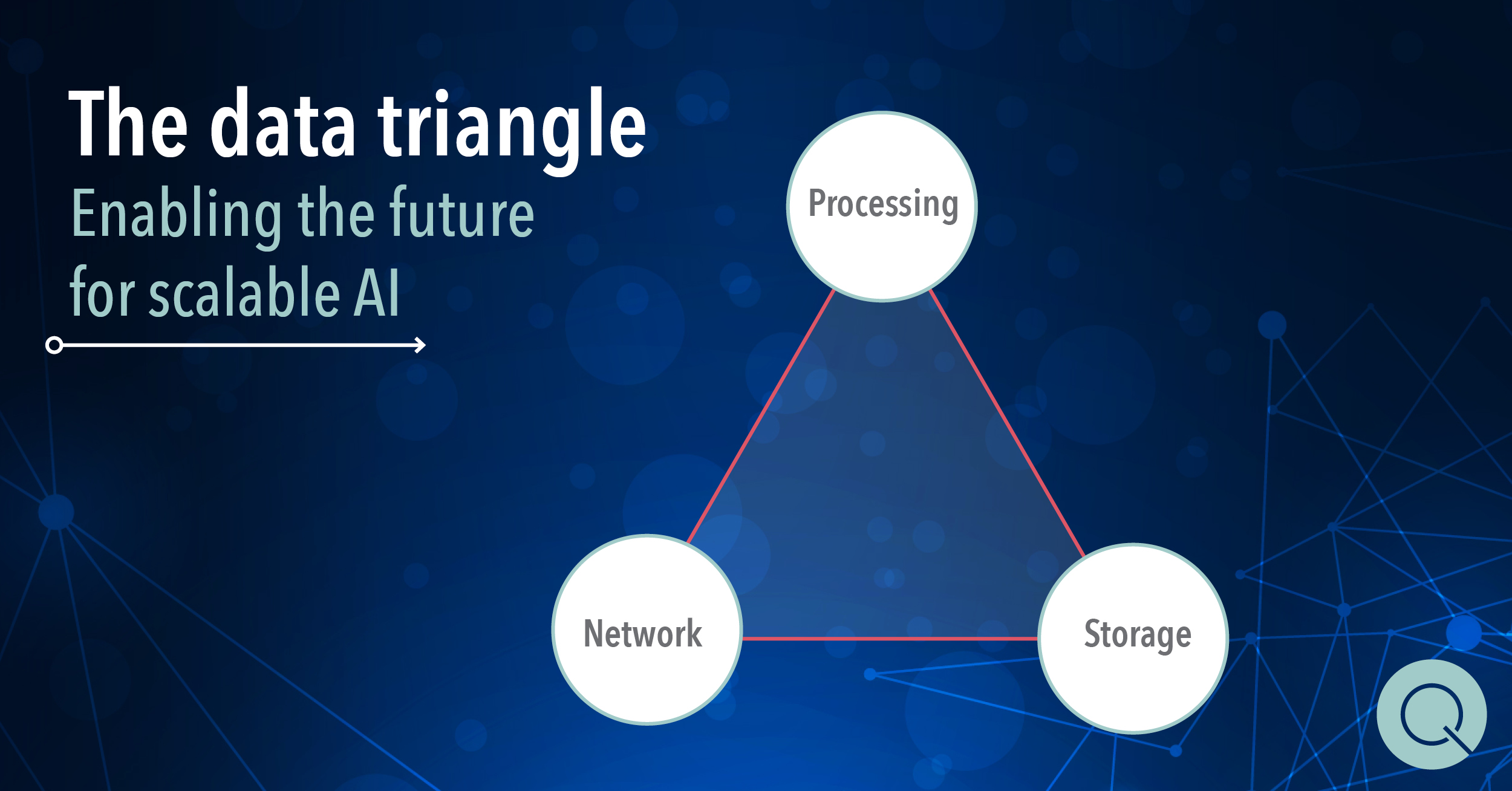
Grohe generally considers processing to be graphic processing units (GPUs) and traffic to be network capacity and speed. Speaking about networks, you need to be able to move data quickly “otherwise you are like a fast car stuck at a toll gate”, said Grohe.
Storage is not just about the volume of data (which is very important) and Grohe advocates that the solution is a parallel file system.
A parallel file system is a type of distributed file system that distributes data across multiple servers, or nodes. This is important because it enables people to be working with the same data, on the same problem, at the same time.
Grohe presented a simple analogy likening it to people being able to collaborate using Google Docs versus trying to work in a single instance of word file. “how do you get all the people who want to add value out of latency mode into productivity mode.”
Leading technologies in this space, like Weka are also enabling scalability and cost efficiencies. In one example Grohe shared, Genomics England had 28 Petabites of storage which required ten (FTE) storage administrators. After moving to Weka, Grohe said they now have 70 petabites of capacity, two and a half times the original capacity, and as a result of built in performance management features like proc cell self-tuning, they were able to reduce the required number of storage administrators to one person, a 90% decrease on the original resourcing requirement.
Data and AI capability for competitive advantage.
In the ultra-competitive environment that many businesses operate in, competitive advantages are a strategic weapon.
It recently struck me in a client meeting, that AI-based capabilities, used to create strategic advantage, can be exponentially more powerful. Competitive advantages are often visible, known and quantifiable to competitors. The size and locations of a branch network, the accessibility of services, exclusivity in markets or specific products, technology capabilities or specific attributes of an offer.
AI capabilities are most likely not externally visible externally and provide businesses with an opportunity to build competitive advantages that exponentially enable businesses and are not easily identifiable or replicable.
Take for example capability that predicts (and alerts businesses) about customers who are at risk of attrition and why they are an attrition risk, or predicts which customers will accept pricing increases and what level of pricing increase without negative impact on volume to optimise revenue. To implement initiatives like these would create strategic advantage that optimises business performance and would be very hard to identify or understand without access to inside knowledge.
These are examples of capabilities which are possible now, but they are reliant on data.
AI capability is for businesses of all sizes.
A reoccurring theme which I am hearing come through in many of my conversations is that ‘AI’ is not just for enterprise. Particularly with the growth of cloud-based offerings, smart technologies are becoming democratized and more accessible and viable than ever.
Applied strategically, the powerful opportunity of AI capability is to remove the competitive barriers between small and large businesses. Addressing this point Grohe referred to the quote “It’s not big eat small, it’s fast eat slow.”
The cost of data misuse.
In 2016 a Forbes article reported that “between 60% and 73% of all data within an enterprise goes unused for analytics”, according to Forrester. A stat which Ken Grohe from Weka believes is still true, four years later.

According to Grohe this means that a large amount of data is not available to people who need to use it, at the time they need to use it.
I distil this down to three negative implications:
One: Productivity
Businesses are recreating or duplicating the existing data at a point of use, resulting in lost productivity.
Two: Decision Quality
Businesses are making decisions without all the data that could be used, necessarily decreasing the validity of business decisions and data driven outputs.
Three: Opportunity Cost
The real cost of data is the opportunity cost of how the unused data could have been used to optimise revenue or decrease costs. How many customers never purchased a product or service, but would have if you had known to make an offer, how many customers would have had a positive experience, but had a poor one because you were never alerted, how many customers attrite, because your customer services never knew to intervene.
While Grohe believes the Forrester claim is still true, the conditions are right for the tide to turn and there are three factors which are helping businesses change their data fortunes.
One: Technology Capability and Accessibility
Technological capability relating to data storage, data processing and data access are rapidly evolving and becoming accessible to businesses of all sizes.
Two: Education and Understanding
Businesses are becoming aware of an acknowledging the importance of data and the role data plays in future operating models.
Three: Skills and Resource
While recognised as a global shortage, human skills, knowledge and experience are developing in the market. Large enterprises are creating senior data leadership positions and medium and small businesses are able to access these skills through local and global freelance resources and the gig economy.

Ken Grohe gives three pieces of advice for data transformation.
Where do you start when thinking about building or transforming data capability? I asked Ken Grohe for three pieces of advice that he would offer and interestingly the first, was one that I promote actively:
Start small but think big
A barrier to businesses can be trying to account for the complexity of long-term transformation. The importance is not necessarily having a highly detailed three-year plan laid out, rather it is starting. Think big, know what your vision is, know what transformation has to deliver for your business in the long run. This will be your compass. But the real importance is to start. Starting small means, you can start fast, you can reduce risk and you can begin transform.
I also like to extend this by saying that starting small can also mean delivering rapid benefit while creating a foundation for long-term transformation.
Have a clear data strategy to support transformation
How will you use technology to build competitive advantage? Is it in customer service, supply chain or manufacturing? Wherever it is and whatever capability you want to enable, the next question will come down to data and the necessity for a clear data strategy.
What data do you already have, what data is required or what data is there that available and could be collected but is not. How will the collection of data, the storage or the accessibility of data need to be optimized?
These are all questions you will have to answer to achieve long term transformation.
Triangulate between GPU, network and a parallel file system
If you are moving to a data-powered future, your success will be based on how quickly you can process data, how quickly you can move it through your network and the ability to scale both the capacity of data your are holding, and the ability to get all of your people out of ‘latency mode’ to be working and collaborating simultaneously.
The data triangle, as described by Grohe is the foundation of your data capability.

